

BERT(トランスフォーマーからの双方向エンコーダー表現)は、最近の自然言語処理(NLP)の進歩である。
これは、ChatGPTやGoogle Bardよりも前の2018年に開発されたGoogleのツールで、検索クエリに含まれる単語を、その文脈や複雑さを考慮することで、以前よりも正確に理解するように設計されている。
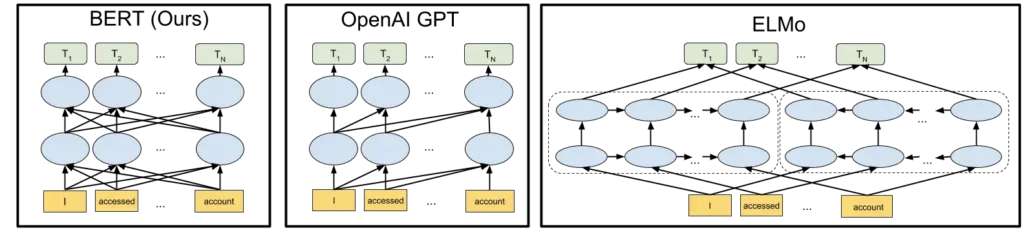
テキストを単一方向(左から右、または右から左)に分析する以前のモデルとは異なり、BERT は、フレーズ内の他のすべての単語に関する単語を双方向に分析する。
単語の前後の単語を分析することで、BERTはその完全な文脈を理解することができ、言語をより深く理解することにつながる。
BERTは、OpenAIのGPT、XLNet、GoogleのTransformerXL、ERNIE2.0、Robertaなど、多くのNLPアーキテクチャ、学習アプローチ、言語モデルに影響を与えている。
BERTとは?
BERTは、柔軟で強力なAIおよび機械学習ツールです。センチメント分析、名前付きエンティティ認識、質問応答など、NLPの様々なアプリケーションで使用されており、AIや機械学習の分野において多用途で強力なツールとなっています。
また、検索エンジンによるユーザーの意図の解釈の改善への貢献は信じられないほど革新的であり、人と機械の間のより自然で人間的なインタラクションの方向への重要な転換点となった。
このモデルは、ウィキペディア(約25億語)やブックコーパス(8億語)など、ラベル付けされていないテキストで事前にトレーニングされている。
変換器の登場以前は、自然言語のモデリングは困難な作業だった。リカレントや畳み込みなどのニューラルネットワークが台頭してからも、その成果は部分的なものに過ぎなかった。
ニューラルネットワークのメカニズムを使って文中の欠落語を予測することは困難だった。ニューラルネットワークは当時、エンコーダー・デコーダー・アーキテクチャに依存しており、強力ではあったが、時間とリソースを消費するメカニズムであった。
バートの仕事ぶり
BERT アーキテクチャは Transformer の上に構築される。利用可能な2つのバリエーションは、BERT Baseである:12層とBERT Large: 24層です。
BERTベースのアーキテクチャは、OpenAIのChatGPTのモデルサイズに似ています。これらのTransformerレイヤーはすべてEncoder専用ブロックです。
テキスト処理
BERT 開発者は、モデルの入力テキストを表現するために、特定のルールセットを追加した。すべての入力埋め込みは、Position Embeddings、Segment Embeddings、Token Embeddings を組み合わせている。
以下の前処理ステップを組み合わせることで、BERT をさまざまな NLP タスクで容易に学習させることができ、モデルのアーキテクチャを変更する必要がない。
- 位置埋め込み:BERTはこれらの埋め込みを学習して使用し、文中の単語の位置をナビゲートする。一連の情報を捉えることができないRNNとは異なり、これらの埋め込みはTransformerがその限界を克服するのに役立つ。
- セグメント埋め込み:BERT は、Question-Answer の場合、文のペアを入力として受け取る。このモデルは、その埋め込みを学習することで、第1文と第2文を区別することができる。
- トークンの埋め込み:これらの埋め込みは、WordPieceトークン語彙から特定のトークンに対して取得された特定の知識を表します。
事前学習タスク
BERT は、マスク言語モデリングと次文予測で事前に訓練されている。もともと、BERT は「双方向」モデルとして設計された。これは、ネットワークがトークンの右文脈と左文脈の両方から、最初の層から最後の層まで情報を取得することを意味する。
これまでの言語モデルは、右から左への文脈予測や、その逆の予測によってエラーを起こしがちだった。
ELMoは、左から右へのテキストと右から左へのテキストを処理する2つの別々のLSTMモデルを学習し、その出力を組み合わせることで、基本的な双方向性を導入した。
BERTは、マスク言語モデル(MLM)アプローチを使用した、より深く純粋な双方向モデルによって、このコンセプトを発展させた。
MLMでは、文中のランダムな単語がマスキングされ、モデルは、連続する次の単語ではなく、これらの隠れた単語を予測するように学習される。
BERTは、学習を強化し、マスク・トークンへの過剰適合を防ぐために、単語の15%をマスクする戦略を採用している。
BERT は、文と文の間の関係を理解する必要があるタスクのための次文予測についても学習される。二値分類タスクの場合、任意のテキスト・コーパスからデータを生成するには、マスク言語モデル(MLM)で使用されるアプローチと同様に、文のペアを作成する必要がある。
例えば、100,000文のデータセットがあれば、50,000の学習ペアが作成できる。これらのペアの半分は、最初の文の直後に2番目の文が続く「IsNext」とラベル付けされ、残りの半分は、最初の文とコーパスからのランダムな文がペアになり、「NotNext」とラベル付けされる。
この方法とMLMは、BERTが異なるタスクに適応する能力の鍵であり、事前学習において次文予測(NSP)とMLMを統合することで、BERTは真にタスクにとらわれないモデルとなる。
BERTのバリエーションと適応
BERT はオープンソースであるため、開発者はソースコードにアクセスし、改良を加え、機能を追加することができる。その結果、多くの BERT 変種が作成されている。以下は、BERT の亜種の一部である。
ロベルタ
これは、Meta社がワシントン大学と共同で作成したBERTの亜種で、「Robustly Optimized BERT approach」の略である。
この変種は、BERTより10倍大きなデータセットで訓練され、オリジナルのBERTより強力であると考えられている。静的マスキング学習の代わりに動的マスキング学習を使用し、よりロバストで汎化可能な単語表現を学習する。
ディスティルバート
これは、事前学習中に知識蒸留技術を使用するオリジナルの BERT のアーキテクチャに基づいている。BERTのサイズを40%縮小し、言語理解能力を97%保持し、60%高速化することで、BERTをより利用しやすくすることを目的としている。
アルベルト
ALBERT(A Lite BERT の略)は、メモリ制約、長いトレーニング時間、およびモデル劣化の問題に対処することで、BERTlarge の事前トレーニング効率を向上させるために開発されました。
ALBERTの開発者は、メモリ使用量を最小限に抑え、トレーニング速度を加速するために、2つのパラメータ削減戦略を導入しました。
Word2VecからBERTへ:NLPの旅
NLPはさまざまなタスクがある多様な分野であるため、タスクに特化したデータセットでは、人間がラベル付けした訓練例は数百から千程度しかない。NLPの旅は、Word2VecやGloVeのような単語埋め込みから始まった。
これらの埋め込みは、単語間の文脈的な関係をとらえ、より良い予測を行うことができた。
しかし、これらの埋め込みは浅い言語モデルを使用していた。得られる情報が限られているため、より複雑な言語モデルを使わなければならなかった。もうひとつの限界は、これらのモデルでは単語の文脈を考慮できないことだった。
ELMoは、単純なWord2Vecモデルから、双方向LSTMネットワークによって生成される複雑な文脈依存埋め込みモデルへと進化することで、多義性というNLPの課題に対処した。
この革新的な技術により、単語は複数の文脈固有の埋め込みを持つことができるようになり、自然言語処理開発における事前学習の利点が浮き彫りになった。
ULMFiTは、最小限のデータで文書分類のための言語モデルの微調整を可能にすることで、NLPをさらに発展させ、NLPにおける効果的な転移学習を100件未満で実証した。これにより、この分野における転移学習の成功の方程式が確立された。
(ULMFiTやELMoで使用されているLSTMモデルよりもTransformerベースのアーキテクチャを採用することで、推論や理解を含むより広範なタスクに対する微調整が容易になった。
GPTは、そのアテンションメカニズムを通じて、Transformerの効率性とパターン認識能力を実証することができ、新たなベンチマークを設定することでアーキテクチャの有効性を強調し、BERTやその後のNLP革新への道を開いた。
Google BERTは何に使われているのか?
BERTは、複数のNLPタスクにおいて最先端の結果を達成することができました。以下は、BERTが得意とする分野の一部です。
- BERTは、トランスフォーマーを搭載した初のチャットボットであり、質問回答において目覚ましい成果を上げている。
- BERTは、映画批評の印象的な悲観的/楽観的予測を示している。
- BERTはすでに、簡単なプロンプトで長い文章を作ることができる。
- BERTは、法律や医療などの簡単な文章から複雑な文章まで要約することができます。
- BERT は、他の言語に適切に翻訳できる多言語モデルである。
- BERT は、電子メールやメッセージング・サービスのような自動補完タスクに使用できる。

特定のタスクのためにBERTを微調整する
大規模言語モデルの最も重要な特徴の1つは、事前学習と微調整を分離することです。開発者は、あらゆるモデルの事前学習済みバージョンを使用し、特定のユースケースのためにそれらを微調整することができます。BERTの微調整バージョンは、さまざまなNLPタスク用に開発されている。
- BERT-base-Chineseは、中国語のNLPタスクのために訓練されている。
- BERT-base-NERは、名前付きエンティティ認識のためにカスタマイズされたバージョンです。
- Symps_disease_bert_v3_c41は、自然言語チャットボット用の症状から疾患への分類モデルです。
- BERT for Patent は、BERTarge をベースとし、Google が世界中の 1 億件以上の特許についてトレーニングしたものです。
BERTとビッグデータの類似点
ビッグデータとBERTは用途が異なるが、大量のデータを扱い分析するという点では基本的に同等である。
その拡張性が両者を際立たせている:BERT は、その言語理解能力を大規模テキスト・データベースから得ている。ビッグデータ技術は、分散システム全体で膨大なデータセットを効率的に処理し、保存するように設計されている。
どちらも複雑な処理方法に依存している:BERTは自然言語処理にディープラーニングとTransformerアーキテクチャを使用し、ビッグデータは分析にHadoopやSparkのような複雑なフレームワークを使用する。
これにより、膨大なデータベースの中に隠されたパターンやトレンド、文脈上の複雑さを見つけることが可能になり、さまざまな分野にわたって洞察や情報に基づいた意思決定を促進することができる。
ビッグデータとBERTは、それぞれの領域における技術的進歩を象徴しており、データサイエンスと人工知能の知識と能力を拡大する上で、大規模データ分析が果たす重要な役割を浮き彫りにしている。
BERTの限界
BERTは、他の大規模言語モデル(LLM)と同様に、学習データの質と量に影響され、限られたデータや偏ったデータは、不正確な結果や「LLMの幻覚」につながる可能性があります。
信頼性を向上させるために人間のフィードバックからの強化学習(RLHF)を使用する新し いモデルとは異なり、オリジナルの BERT にはこの機能が欠けている。この欠落により、人間による訓練調整の利点がなく、エラーが発生しやすくなっている。
さらに、BERT は同世代の製品よりも小型であるにもかかわらず、運用と訓練にかなりの計算資源を必要とするため、 リソースに制約のある開発者にとっての課題となっている。
結論
結論として、BERT は言語モデリングにおける複雑さと進歩の頂点を示し、言語理解の自動化を新たな高みへと押し上げた。
膨大なデータセットに対する広範な訓練とTransformerアーキテクチャの変革的な使用によって比類のない性能を達成したBERTは、NLPに多大な影響を与えた。
BERTのオープンソース化と、AIコミュニティによる新しいイテレーションの強化と配布への献身 BERTのオープンソース化と、AIコミュニティによる新しいイテレーションの強化と配布への献身によって、将来は、NLPにおいてまだ達成されていないマイルストーンで満たされることが約束される。
よくある質問
BERTとトランスフォーマーの比較とは?
BERT が単語の埋め込みを生成するのに対して、Sentence Transformers は、文や段落を含む、より広範なテキスト・セグメントの理解を得意とする。これらのモデルは、詳細な文埋め込みを作成するように設計されており、文レベルの理解を必要とする様々なアプリケーションに適しています。
BERTはGPTより優れているのか?
BERTは、文節間のつながりを理解することが不可欠な、感情分析、質問応答、テキスト分類などのタスクに優れています。逆に、GPTはテキスト生成、特に自然な響きのテキストを作成することに優れている。
BERTに続いて、NLPは今後どのような発展を遂げるのでしょうか?
BERT の成功は、より効率的で、正確で、汎用性の高い NLP モデルの研究に拍車をかけている。将来の進歩には、より少ない計算能力で、文脈をより深く理解し、より幅広い言語やタスクに容易に適応できるモデルが含まれるかもしれない。
BERT との協働を開始するためのリソースはどこにありますか?
BERT の使用を検討している開発者は、Google と Hugging Face の Transformers ライブラリによって維持されている公式 GitHub リポジトリを通じて、訓練済みモデルとドキュメントにアクセスすることができます。



